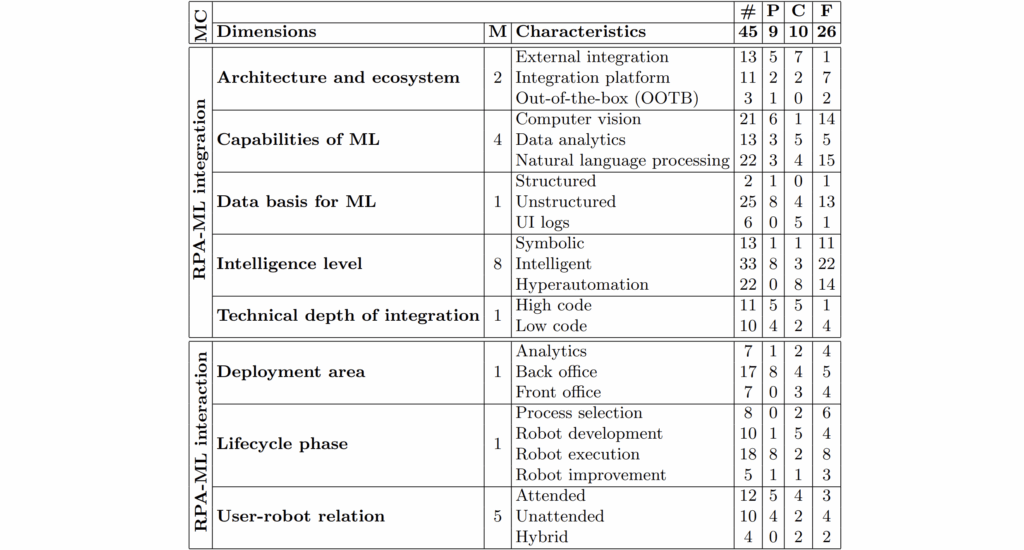
Legend: MC meta-characteristics, M mentions, # total, P practitioner reports, C conceptions, F frameworks
Recent developments in process automation have revolutionized business operations, with Robotic Process Automation (RPA) becoming essential for managing repetitive, rule-based tasks. However, traditional RPA is limited to deterministic processes and lacks the flexibility to handle unstructured data or adapt to changing scenarios. The integration of Machine Learning (ML) into RPA—termed intelligent RPA—represents an evolution towards more dynamic and comprehensive automation solutions. This article presents a structured taxonomy to clarify the multifaceted integration of ML with RPA, benefiting both researchers and practitioners.
RPA and Its Limitations
RPA refers to the automation of business processes using software robots that emulate user actions through graphical user interfaces. While suited for automating structured, rule-based tasks (like «swivel-chair» processes where users copy data between systems), traditional RPAs have intrinsic limits:
- They depend on structured data.
- They cannot handle unanticipated exceptions or unstructured inputs.
- They operate using symbolic, rule-based approaches that lack adaptability.
Despite these challenges, RPA remains valuable due to its non-intrusive nature and quick implementation, as it works «outside-in» without altering existing system architectures.
Machine Learning: Capabilities and Relevance
Machine Learning enables systems to autonomously generate actionable knowledge from data, surpassing expert systems that require manual encoding of rules. ML includes supervised, unsupervised, and reinforcement learning, with distinctions between shallow and deep architectures. In intelligent RPA, ML brings capabilities including data analysis, natural language understanding, and pattern recognition, allowing RPAs to handle tasks previously exclusive to humans.
Existing Literature and Conceptual Gaps
Diverse frameworks explore RPA-ML integration, yet many only address specific facets without offering a comprehensive categorization. Competing industry definitions further complicate the field, as terms like «intelligent RPA» and «cognitive automation» are inconsistently used. Recognizing a need for a clear and encompassing taxonomy, this article synthesizes research to create a systematic classification.
Methodology
An integrative literature review was conducted across leading databases (e.g., AIS eLibrary, IEEE Xplore, ACM Digital Library). The research encompassed both conceptual frameworks and practical applications, ultimately analyzing 45 relevant publications. The taxonomy development followed the method proposed by Nickerson et al., emphasizing meta-characteristics of integration (structural aspects) and interaction (use of ML within RPA).
The Taxonomy: Dimensions and Characteristics
The proposed taxonomy is structured around two meta-characteristics—RPA-ML integration and interaction—comprising eight dimensions. Each dimension is further broken down into specific, observable characteristics.
RPA-ML Integration
1. Architecture and Ecosystem
- External integration: Users independently develop and integrate ML models using APIs, requiring advanced programming skills.
- Integration platform: RPA evolves into a platform embracing third-party or open-source ML modules, increasing flexibility.
- Out-of-the-box (OOTB): ML capabilities are embedded within or addable to RPA software, dictated by the vendor’s offering.
2. ML Capabilities in RPA
- Computer Vision: Skills like Optical Character Recognition (OCR) for document processing.
- Data Analytics: Classification and pattern recognition, especially for pre-processing data.
- Natural Language Processing (NLP): Extraction of meaning from human language, including conversational agents for user interaction.
3. Data Basis
- Structured Data: Well-organized datasets such as spreadsheets.
- Unstructured Data: Documents, emails, audio, and video files—most business data falls into this category.
- UI Logs: Learning from user interaction logs to automate process discovery or robot improvement.
4. Intelligence Level
- Symbolic: Traditional, rule-based RPA with little adaptability.
- Intelligent: RPA incorporates specific ML capabilities, handling tasks like natural language processing or unstructured data analysis.
- Hyperautomation: Advanced stage where robots can learn, improve, and adapt autonomously.
5. Technical Depth of Integration
- High Code: ML integration requires extensive programming, suited to IT professionals.
- Low Code: No-code or low-code platforms enable users from various backgrounds to build and integrate RPA-ML workflows.
RPA-ML Interaction
6. Deployment Area
- Analytics: ML-enabled RPAs focus on analysis-driven, flexible decision-making processes.
- Back Office: RPA traditionally automates back-end tasks, now enhanced for unstructured data.
- Front Office: RPA integrates with customer-facing applications via conversational agents and real-time data processing.
7. Lifecycle Phase
- Process Selection: ML automates the identification of automation candidates through process and task mining.
- Robot Development: ML assists in building robots, potentially through autonomous rule derivation from observed user actions.
- Robot Execution: ML enhances the execution phase, allowing robots to handle complex, unstructured data.
- Robot Improvement: Continuous learning from interactions or errors to improve robot performance and adapt to new contexts.
8. User-Robot Relation
- Attended Automation: Human-in-the-loop, where users trigger and guide RPAs in real time.
- Unattended Automation: RPAs operate independently, typically on servers.
- Hybrid Approaches: Leverage both human strengths and machine analytics for collaborative automation.
Application to Current RPA Products
The taxonomy was evaluated against leading RPA platforms, including UiPath, Automation Anywhere, and Microsoft Power Automate. Findings revealed that:
- All platforms support a wide range of ML capabilities, primarily via integration platforms and marketplaces.
- Most ML features target process selection and execution phases.
- The trend is toward increased low-code usability and the incorporation of conversational agents («copilots»).
- However, genuine hyperautomation with fully autonomous learning and adaptation remains rare in commercial offerings today.
Limitations and Future Directions
The taxonomy reflects the evolving landscape of RPA-ML integration. Limitations include:
- The dynamic nature of ML and RPA technologies, making the taxonomy tentative.
- Interdependencies between dimensions, such as architecture influencing integration depth.
- The need for more granular capability classifications as technologies mature.
Conclusion
Integrating ML with RPA pushes automation beyond deterministic, rule-based workflows into domains requiring adaptability and cognitive capabilities. The proposed taxonomy offers a framework for understanding, comparing, and advancing intelligent automation solutions. As the field evolves—with trends toward generative AI, smart process selection, and low-code platforms—ongoing revision and expansion of the taxonomy will be needed to keep pace with innovation.
Paper: https://arxiv.org/pdf/2509.15730
